
Summary :
The article discusses the challenges faced by Security Operations Center (SOC) and Detection Engineering teams in creating and maintaining detection rules amid a growing cyber threat landscape and expanding enterprise environments. It highlights the importance of ongoing monitoring and the need for adaptable detection strategies. #CyberSecurity #DetectionEngineering #ThreatIntelligence
Keypoints :
- Detection engineers face challenges due to the increasing number and complexity of cyber attacks.
- Enterprise environments are evolving towards hybrid models, complicating detection efforts.
- Attackers reuse existing TTPs, making it essential for defenders to track these techniques.
- Log standardization and normalization remain significant hurdles for detection engineering.
- Phishing AiTM attacks illustrate the need for adaptable detection rules across various platforms.
MITRE Techniques :
- Phishing (T1566): Procedures (Phishing AiTM attacks target users through fake Office links to capture credentials).
- Credential Dumping (T1003): Procedures (Attackers may use intercepted cookies to access victim accounts).
Indicator of Compromise :
- [domain] typosquatted[.]domain
- [email] user.email
- [tool name] Microsoft 365
- [tool name] Microsoft Entra ID
Table of contents
Security Operations Center (SOC) and Detection Engineering teams frequently encounter challenges in both creating and maintaining detection rules, along with their associated documentation, over time. These difficulties stem largely from the sheer number of detection rules required to address a wide range of technologies.
Sekoia.io introduces this series of articles aiming to present an approach designed to address these challenges. It introduces our detection approach and some related problems, outlines the regular and automated actions performed through CI/CD pipelines, and highlights the importance of incorporating ongoing monitoring and review into the detection engineering process, despite these measures.
A Two-Faced issue
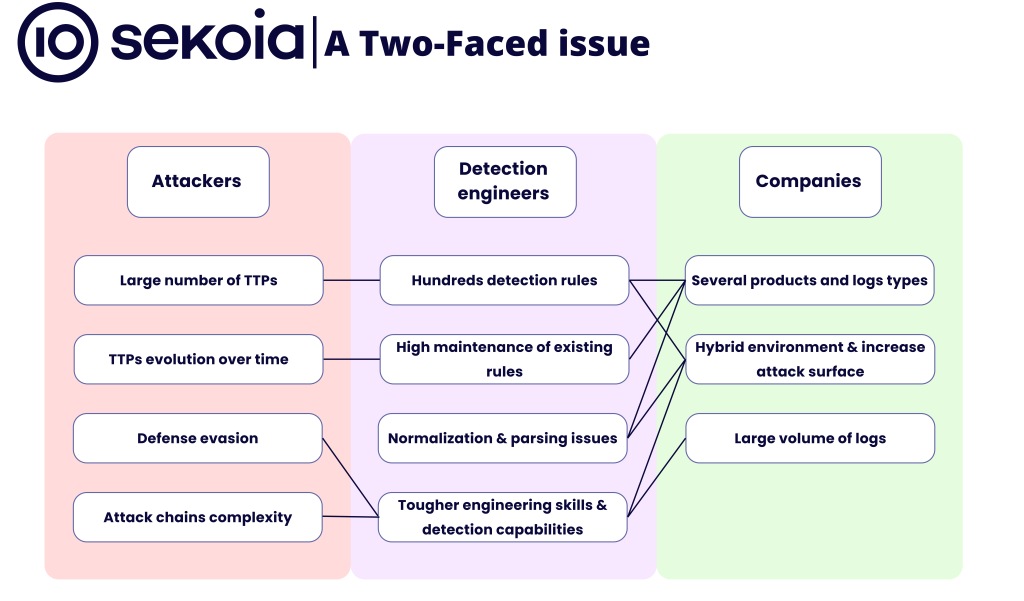
The challenges faced by detection engineers today can be viewed as twofold: on one hand, the number and complexity of attacks continue to increase; on the other hand, enterprise environments are expanding, transitioning to hybrid models, and exposing a larger attack surface.
In the first article of this series, we will discuss the challenges at hand and provide practical examples to illustrate them.
Attackers on the rise
The cyber threat landscape has evolved significantly over the past decade. This evolution has resulted in a dramatic increase in both the number of attackers and the variety of Techniques, Tactics, and Procedures (TTPs) they employ. Fortunately, not every new attacker introduces a unique TTP. Attackers often reuse existing TTPs, which helps streamline the work of detection engineers.
From a defender perspective, it is essential to follow all of these TTPs, and try to detect the most used ones. As an example, the Sekoia.io rules catalog currently lists almost a thousand rules mapped to the MITRE ATT&CK matrix. Still, this does not fully cover the matrix, which is continually evolving, as demonstrated by regular updates to the MITRE ATT&CK framework. Furthermore, attackers frequently seek to avoid detection, for instance by leveraging legitimate binaries, underscoring the importance of this issue. The LOLBAS (Living Off The Land Binaries, Scripts, and Libraries) project, along with other comparable initiatives, provides valuable insights into the scope of this challenge.
An important point for defenders building detection rules for various customers is also that not every rule can be deployed everywhere for a given TTP. A recent example is the ClickFix social engineering tactic. This tactic involves displaying fake error messages in web browsers to deceive users into copying and executing a given malicious PowerShell code, finally infecting their systems. If detection engineers only rely on the common host and network events, it will result in difficulties to build a generic approach and would need some heavily customised filters. For further in depth details, please check our related blogpost.
Defense all over the place
On the other side, enterprise environments have also changed, with organisations now operating in hybrid setups and utilising a diverse array of products. While these advancements sometimes enhance security and provide access to a greater volume of logs, they also pose significant issues for detection engineers.
The access to large volumes of logs presents significant challenges in processing data and applying detection rules at scale. Additionally, it becomes increasingly difficult for both detection engineering and integration teams to analyse the logs, parse them, and develop effective detection rules.
The lack of standardisation in the logs generated by hundreds of different products, combined with the sheer volume of data, makes parsing and normalisation particularly difficult. These processes, which have always been critical to detection, have become increasingly complex over time. As a result, detection rules often face issues such as multiple conditions required to handle improperly normalised fields or, more frequently, values.
When it comes to cloud-related detection rules, normalisation often becomes an unattainable goal. Each cloud provider – whether AWS, GCP, Azure, or others – employs unique event structures and fields, making standardisation across providers extremely challenging.
This complexity is one of the primary reasons why many detection engineering teams accumulate hundreds, if not thousands, of detection rules over time. These rules become difficult to manage and nearly impossible to confidently delete, posing maintenance constraints. This situation benefits no one, as it often leads to alert fatigue for SOC analysts, who must contend with frequent false positives triggered by an overabundance of detection rules.
The schema below summarises these two key issues, providing an overview before delving into some concrete examples.
Practical example
A detection use case we recently faced, that could illustrate our concern, is related to the phishing AiTM (Adversary-in-The-Middle) attack. It is increasingly popular among attackers targeting personal or corporate documents that are stored in a cloud solution.
The typical attack scenario steps, which are also illustrated in this video, are:
- The user receives an email containing a fake Office link to authenticate with its corporate email account.
- The Office link redirects to a typosquatted domain intercepting the access to Microsoft 365 portal, allowing the attacker to catch user login/password and authenticated cookie.
- The attacker re-injects the stolen cookie to access the victim account and exfiltrates its corporate documents.
As outlined in our previous blog post, we chose to use Sigma as our detection language, although this approach can be adapted to other detection languages. Our goal is to create a detection rule that is sufficiently generic to work on various solutions. Starting with Microsoft, we initially developed the following Sigma pattern:
detection:
aitm_source_ip:
sekoiaio.tags.source.ip: AiTM
user.email: ‘*’
microsoft_365_login:
event.action: UserLoggedIn
entra_id_login:
azuread.category: SignInLogs
condition: aitm_source_ip and (microsoft_365_login or entra_id_login)
This Sigma rule combines a first selection based on our Cyber Threat Intelligence (CTI) enrichment along with two other selections that detect user authentication. As shown in the condition field, the rule has two distinct selections according to the Microsoft product’s logs to work with both Microsoft 365 and Entra ID products.
This issue could be resolved by improving normalisation, such as standardising field names and values across both Microsoft 365 and Microsoft Entra ID products but also any other products. By adopting fields based on the Elastic Common Schema (ECS) Reference, we developed the following updated and more generic version:
detection:
aitm_source_ip:
sekoiaio.tags.source.ip: AiTM
user.email: ‘*’
event.category: authentication
condition: aitm_source_ip
This shows that building rules that are “vendor-agnostic” is a constant challenge, especially since sometimes the normalisation is not obvious at first sight for both detection engineers and the team building the logs parsers.
Conclusion
To conclude this first article of the series, detection engineering at scale presents a series of complex and evolving obstacles, as argued throughout this article. The growing sophistication of attacks, along with the expanding and increasingly hybrid enterprise environments, requires detection engineers to continuously adapt their approaches for better coverage. From managing the high volume and diversity of logs to addressing the limitations of normalisation across various platforms, the challenges are significant.
In the subsequent parts of this article’s series, we will delve deeper into our approach, our methodology and process to further streamline and scale detection engineering efforts.
Thank you for reading this blog post. Please don’t hesitate to provide your feedback on our publications by clicking here. You can also contact us at tdr[at]sekoia.io for further discussions.
Full Research: https://blog.sekoia.io/detection-engineering-at-scale-one-step-closer-part-one/