Summary: This content discusses the issue of secrets being exposed in source code, even after they have been removed, and highlights the potential risks and challenges associated with this.
Threat Actor: N/A
Victim: N/A
Key Point:
- Hard-coding secrets into code can permanently expose them, even after removal.
- 18% of secrets may be overlooked by current scanning methods.
- Credentials to cloud environments, internal infrastructures, and telemetry platforms are among the major secrets exposed on the internet.
- Git-based processes and Source Code Management (SCM) platforms can contribute to secrets remaining exposed.
- Advanced strategies are needed to uncover hidden secrets that cannot be detected by popular scanning tools.
For years, we’ve been educating developers not to hard-code secrets into their code. Now it turns out that even doing this once might permanently expose that secret, even after its apparent removal – and worse, most secrets scanning methods will miss it. Our research found that almost 18% of secrets might be overlooked.
We uncovered major secrets, including credentials to cloud environments, internal infrastructures, and telemetry platforms, exposed on the Internet. Through a variety of Git-based processes whose impact is not well understood by developers and AppSec professionals, and Source Code Management (SCM) platforms behavior, secrets remain exposed even after considered removed. In this blog, we will explain each of these scenarios.
Uncovering Hidden Secrets
In this research, we will shed a bright light on advanced strategies for uncovering hidden secrets in your source code. Some of these hidden secrets cannot be discovered by any of the current popular scanning tools. If you care to discover them, you will need to adopt new scanning methods. We will review existing research on various known scenarios and introduce new findings, including case studies on hidden secrets we discovered.
To illustrate the severity of what we review in our research, consider this: by applying one of the strategies we present, we discovered that conventional scanning methods miss nearly 18% of potential secrets in the repositories of the top 100 organizations on GitHub (encompassing over 50,000 repositories). And this is just the tip of the iceberg.
During our research, we uncovered some significant secrets, including gaining access to the complete cloud environments of some of the biggest organizations in the world, infiltrating the internal fuzzing infrastructure of sensitive projects, accessing telemetry platforms, and even obtaining access to network devices, SNMP secrets, and camera footage of Fortune 500 companies.
Case Studies from the Wild
In this research, we present various cases and strategies that allowed us to uncover numerous valid secrets in highly sensitive environments. To motivate you to learn these methods, here are some examples of our findings. These discoveries could lead to significant attacks on the impacted organizations. This highlights how secrets can be missed when users don’t scan their codebase using these strategies.
Get every fuzzing result of Firefox – Mozilla FuzzManager API Token
FuzzManager is an internal tool used by Mozilla to collect, manage, and analyze fuzzing data, which helps identify potential security vulnerabilities and bugs. Due to the sensitive nature of this information, it is not shared publicly to prevent malicious actors from exploiting unpatched vulnerabilities.
During our research, we discovered an API token for Mozilla’s FuzzManager (https://fuzzmanager.fuzzing.mozilla.org) that was leaked in one of Mozilla’s public GitHub repositories. This API token provided access to Mozilla’s internal fuzzing data and results.
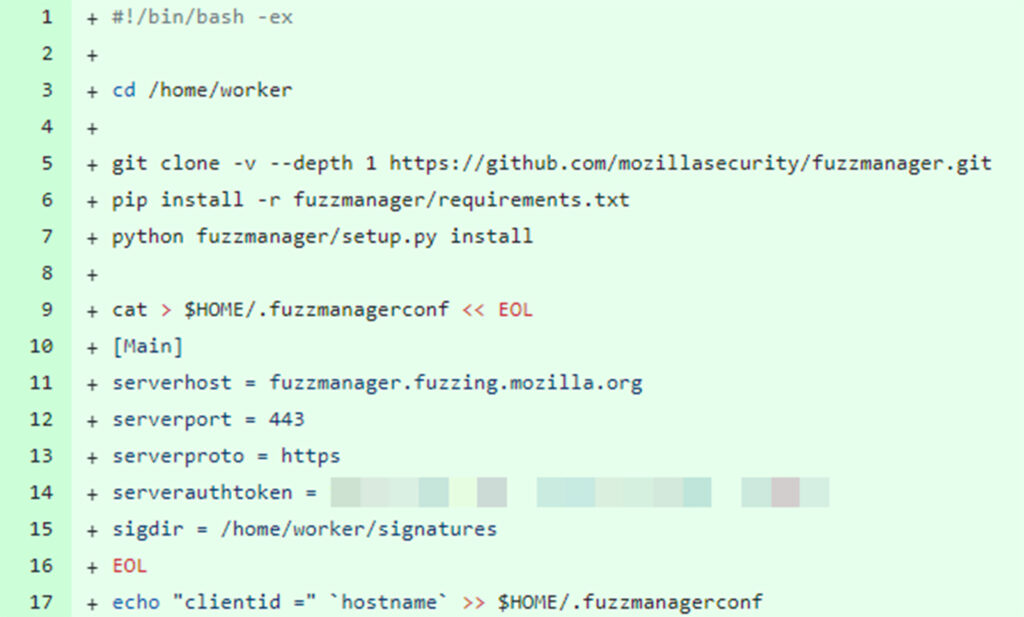
Commit that was only accessible on the mirrored version of the repository and contained a secret
In our proof of concept, we were able to download all the fuzzing results related to the Firefox project from this internal service.
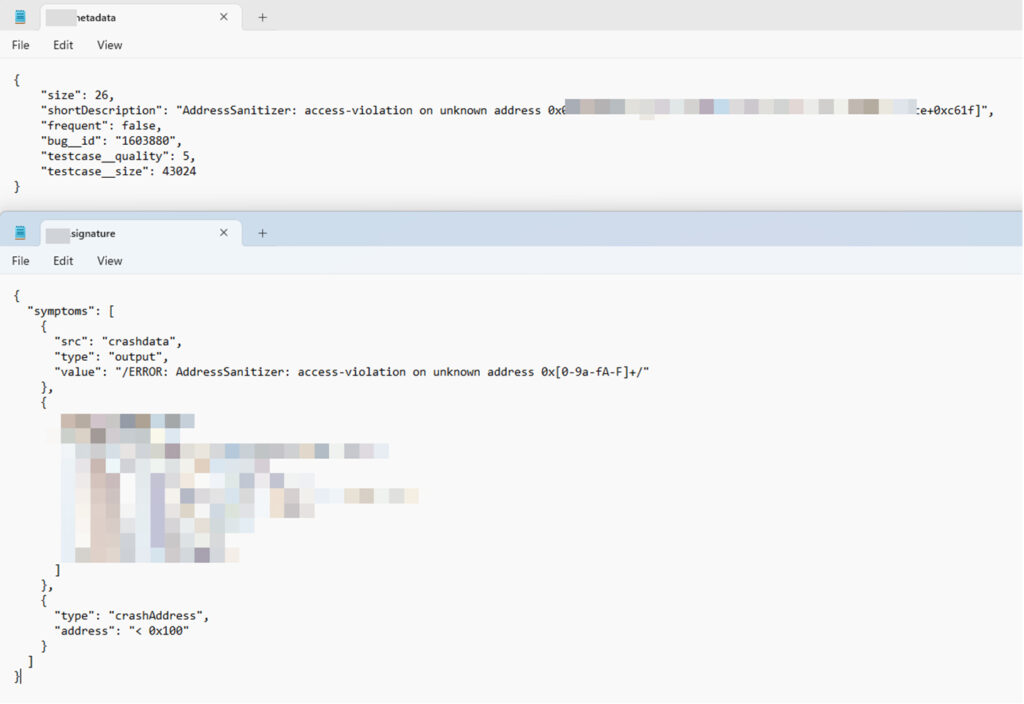
An example of a fuzzing result of Firefox project
To make things worse, the token was mistakenly configured with high privileges, allowing both read and write access. Access to this fuzzing infrastructure could expose known fuzzing results, revealing unpatched security vulnerabilities in the different projects. With detailed information on specific bugs, attackers could craft precise and effective exploits, increasing the risk of successful attacks on users.
The write privilege can be used by an attacker to erase, distort or manipulate fuzzing data, in order to hide an interesting data-point.
It is also important to note that the Tor Browser is based on Firefox. Any vulnerabilities discovered in Firefox through this fuzzing infrastructure could potentially exist in Tor as well, exposing it to similar risks.
We reported our findings to the Mozilla security team, which promptly rotated the token.
Protecting Mozilla’s Telemetry Data: Leaked Employee API Token
Mozilla’s telemetry system collects usage statistics, performance metrics, and other data from Firefox users to enhance browser performance. The telemetry dashboard is used to create queries and dashboards using the aggregated telemetry data of users. The dashboard also allows access to information about Mozilla products and business which is considered confidential company data, therefore, access is generally restricted to authorized personnel only.
During our research, we discovered an API token belonging to a Mozilla employee on the telemetry service (https://sql.telemetry.mozilla.org) that had been inadvertently leaked in one of Mozilla’s public GitHub repositories.
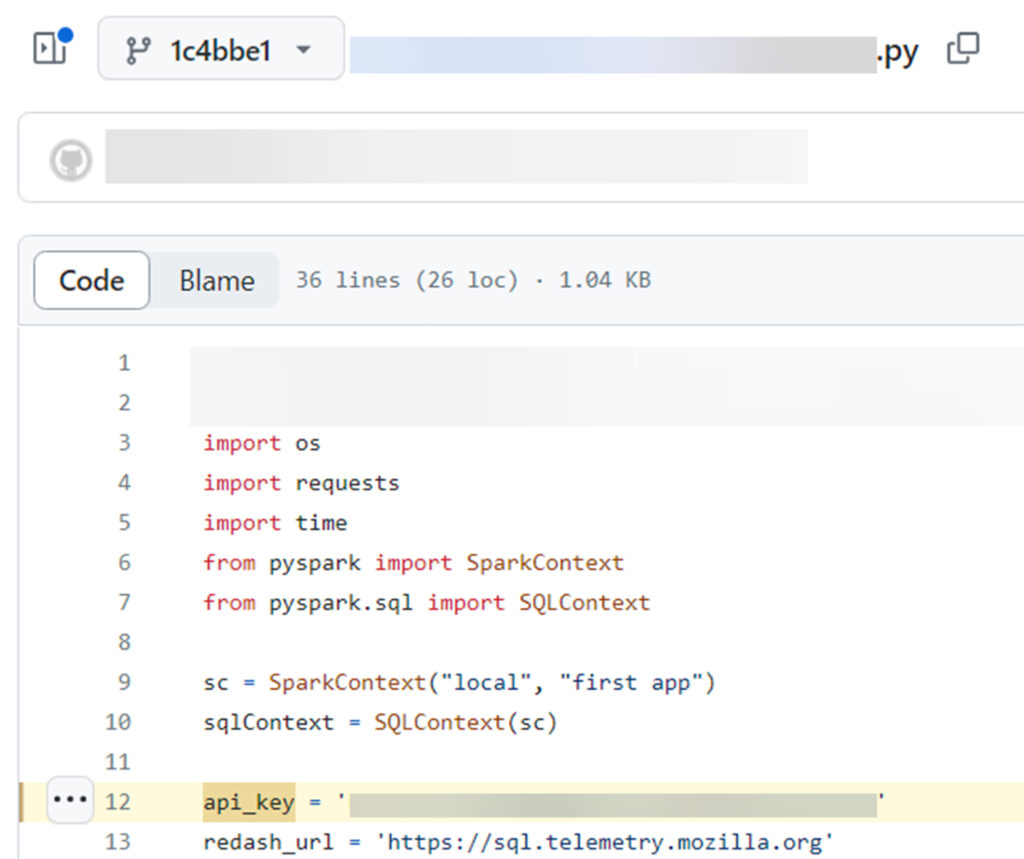
Secret that was exposed in a Git Commit
This token granted access to the service dashboard, which contained confidential data.
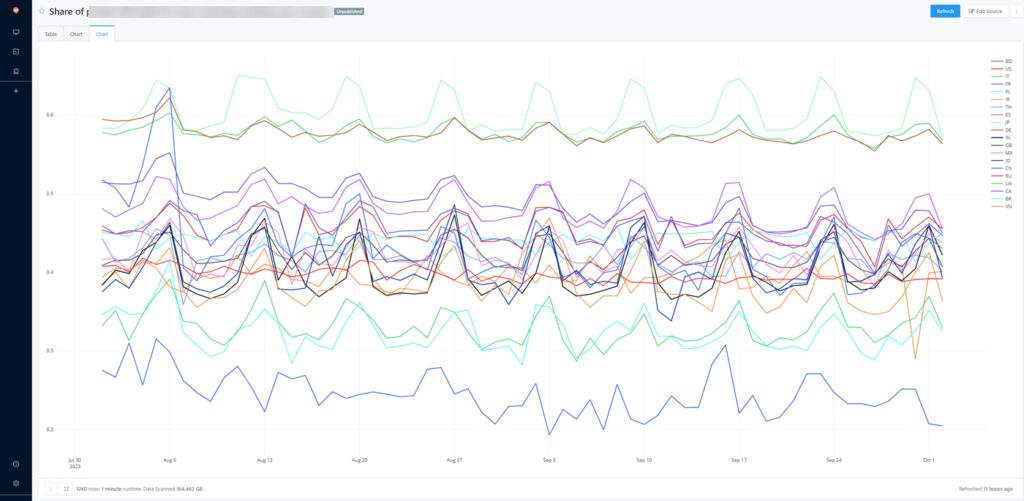
Access to Mozilla telemetry (https://sql.telemetry.mozilla.org) with leaked employee token
Upon identifying this exposure, we promptly reported our findings to Mozilla. They responded immediately by rotating the compromised token and removing it from the service.
Meraki API Tokens of Fortune 500 Companies
Meraki API tokens grant access to the Meraki Dashboard API, which is used for managing network resources. These tokens are extremely sensitive as they offer direct control over network configurations and data. If exposed, the risks include unauthorized access, allowing attackers to seize control of network resources and compromise sensitive information.
During our research, we discovered privileged Meraki API tokens used by some of the Fortune 500 companies. These tokens could allow attackers to access network devices, SNMP secrets, camera footage, and more, serving as an initial foothold for the exposed parties. We reported this issue to the companies involved and to Cisco, which immediately investigated the issue and rotated the tokens.

Retrieving sensitive data, such as SNMP secrets, using the exposed tokens
Healthcare Company Leaves Crown Jewels Unguarded
During our research, we found an Azure service principal token belonging to a large healthcare company exposed in a Git commit.
This token had high privilege on their Azure AD, high access to the company’s internal Azure Kubernetes Service (AKS), their Azure Container Registry (ACR), and many other resources on Azure. For example, the token enabled retrieving admin credentials for their AKS instances, this may lead to full control over the Kubernetes clusters of the organization. The token also allowed to obtain credentials to the internal ACR, which could have led an attacker to perform a supply chain attack, by pushing a malicious container image, impacting the organization, and customers.
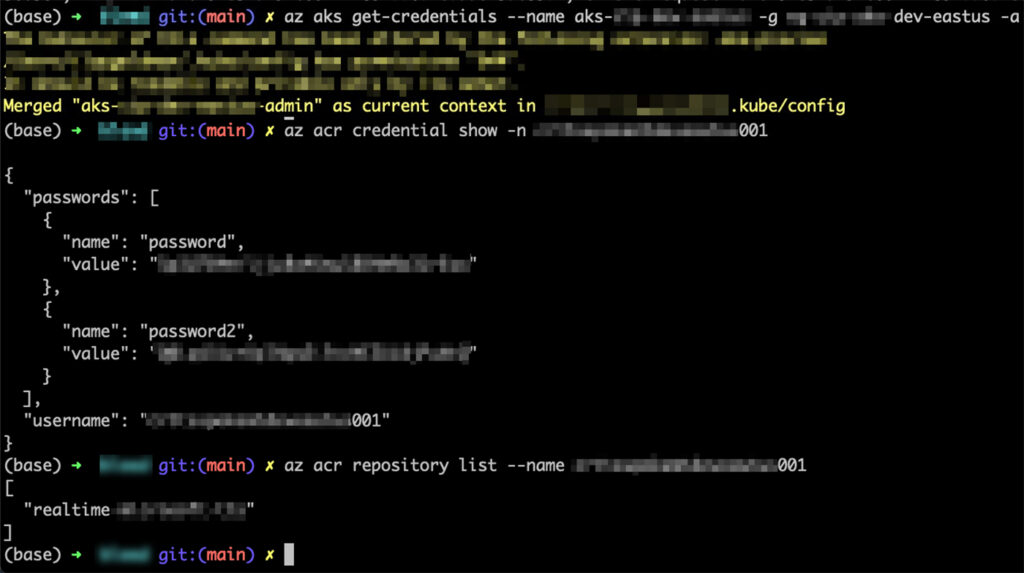
Obtaining AKS and ACR privileged credentials with the leaked Service Principal token
We immediately reported our findings to the company, who promptly rotated the compromised token and investigated the case.
Explaining How We Found These Secrets
Now that we have showcased the value of our research, let’s delve into the techniques that led to these significant findings. First, we’ll start with some background information, basic assumptions, and Git internals before moving on to the details.
Background and Basic Assumptions
In the past we heard a lot of horror stories about leaked secrets in various SCM platforms. Those cases raised great awareness among developers and organizations. Thus, they invested resources using built-in features on some platforms to alert users about possible leaks and prevent secrets from being pushed from the beginning.
Additionally, some companies actively search for leaks of their users’ tokens. Most importantly, many have adopted bug bounty programs. This approach encourages numerous ethical hackers to disclose these secrets and report them to companies before attackers can exploit them.
While these solutions are great and actively reduce a lot of the risks, they often miss secrets as detailed below.
Secrets Scanning Tools and Their Blind Spots
The problem of exposed secrets in source code remains a common and significant challenge in the software development life cycle (SDLC).
Not all secrets scanning tools are alike, the diverse scanning tools vary in the volume of results, and the level of their accuracy.
When building a secrets scanning tool you need to take some basic engineering decisions, for instance will the detection mechanism be based on pattern recognition, or the detection is entropy-based.
This may impact the volume of results. Now you need another algorithm to verify the accuracy of these results, there’s a fine balance between false positive and false negative. These decisions impact the effectiveness of the secrets scanning tool and this leads to the conclusion that companies need to use multiple scanning tools to get maximum results.
Several nuances that further contribute to this complexity:
- API key patterns often do not conform to standard regular expression models, making detection more challenging.
- Hardcoded secrets can be found in unpredictable locations, extending beyond the usual confines of configuration files or URLs parameters.
- Credentials exhibit varying entropy levels, indicating that not all of them will be easily detectable based on complexity.
Nevertheless, there is another dimension to this problem. In some cases, the secrets scanners completely miss vast areas of the code base, due to inherent limitations and the behavior of the SCM platforms, which leads to missed secrets. De-facto there are various commits that remain unscanned or unreachable for the secrets scanners.
Why Do Secrets Scanning Tools Miss Secrets?
Most of the time when you run a secrets scanning on your SCM, you will be using the git clone, command, either actively or behind the scenes in the internals of the scanning tool.
Due to edge cases or design choices of Git and SCM platforms (GitHub, GitLab, Bitbucket, Azure Repos, and more). When using git clone command, you will miss some commits that remain unscanned and unreachable. In this case, these commits may contain secrets that won’t be discovered.
GitHub is a popular platform with plenty of public repositories. Hence, it is often targeted by attackers who launch massive secrets harvesting campaigns. Therefore, in our research we decided to focus on this SCM platform. Nevertheless, we will also show examples from other SCM, to emphasis that this problem isn’t limited to GitHub.
Interestingly, in their documentation GitHub state unequivocally that sensitive data can be exposed via different scenarios, but they don’t explain how and why this exposure happens. It’s unclear for users how this happens and how to find these exposed sensitive data. In this blog we aim to shed a brighter light on most of these scenarios.
Technical Explanation
While there are number of reasons that may lead to missed secrets, we chose to focus in three main categories:
- Secrets that are accessible via
git clone - Secrets that are accessible only via
git clone --mirror - Secrets that are accessible via cached views of SCM platforms
Secret that are accessible via git clone
By referring to secrets accessible only via git clone we mean the most popular methods and approaches for secrets scanning. A workflow, user, DevOps engineer, or researcher runs git clone to clone a project from source control management systems like GitHub and then uses a secrets scanning tool, such as Gitleaks or TruffleHog (There are plenty of secrets scanning tools, but for simplicity, we will focus on the popular ones).

The Iceberg of Secrets: Most secrets will be revealed in cloned versions of a Git repository
Usually, the scan will cover different branches, the commit history, and other areas of the repository. This is the most standard way most of us scan our code. However, there are risks because there is more to scan, and secrets and sensitive data may still exist in your repository.
Secret that are accessible via git clone – -mirror
In short, the command git clone --mirror fetches a copy of your repository that includes all references, such as all remote branches, tags, etc. ensuring a complete copy of the original repository as it exists in the remote/origin (the term origin is the default name for a remote repository).
On February 11, 2022, the cybersecurity consultancy nightwatchcybersecurity released a blog post discussing an issue they named GitBleed (CVE-2022-24975).
The CVE is about the Git documentation regarding the --mirror option, which does not mention the availability of deleted content when a user clones a project with --mirror. This CVE has been disputed by multiple third parties who believe this is the intended behavior of Git.

The Iceberg of Secrets: The next layer of secrets exists in the mirror version of a Git repository.
Anyway, this issue highlights that when scanning a repository for secrets using git clone rather than git clone --mirror, there is a risk of missing sensitive data that exists only in mirrored copies of your repository.
This finding is significant since the majority of users/workflows use the git clone command. What’s even worse is that many scanning tools do not support scanning mirror repositories, or users must use them in a specific way to scan mirrored repositories, leaving users with limited options to scan the repository for secrets.
Which means potentially, there are numerous leaked secrets out there that users don’t yet know they might accidentally reveal, because they never scan the mirror version of their repositories.
What Is a Mirror Repository, and Why Does It Contain More Content?
When we reviewed the GitBleed research, we noticed it lacked a detailed explanation of why the issue is happening. The focus was primarily on describing the issue itself.
Here, we aim to delve deeper into the reasons behind this occurrence, exploring Git’s internal workings to provide a clearer understanding of how and why some secrets are only accessible in the mirror copy of a repository.
As a reminder, in the original research the author claimed that the main gap between the git clone and git clone --mirror commands stem from deleted content. We would like to clarify that the issue is not primarily related to “deleted” content, although that is one aspect. The real reason for discovering additional content on mirrored repositories lies in the behavior of certain SCM platforms, which can be problematic in specific scenarios, as well as the typical behavior of Git, which can be misused by users.
As we mentioned above, mirrored repository includes all references of the original repository as they exist in the SCM.
When we want to get the mirrored copy of our repository, we can use git clone --mirror <repository-url>. This command creates an exact replica of the repository, which is useful for tasks such as creating backups and moving repositories between SCM platforms or hosting servers.
Essentially, when you execute git clone --mirror, you’re instructing it to get every piece of code, every branch, and every commit – the entire repository content.
To understand what is happening behind the scenes when you perform a regular git clone and git clone --mirror, let’s first understand what references are on git.
Basically, references (or refs) are pointers to commits, and git stores information about your repository’s branches, tags, etc., in these data structures.
Branches are stored in references named refs/heads/<branch_name>, and tags are stored in references named refs/tags/<tag_name>. Remote branches are stored in refs/remotes/origin/<branch_name> and pull requests in some SCM platforms are stored in references named refs/pull/<id>, and so on.
A regular branch name like bugfix is actually a reference whose full name is spelled refs/heads/bugfix.
It is unnecessary to write the full name of the reference, and we can omit different parts of its prefix when using commands like git show <reference_name>. For example: refs/remotes/origin/<branch_name> is equivalent to remotes/origin/<branch_name> and origin/<branch_name>.
Remote-tracking branches are references that reflect the state of remote branches. They are local references that you cannot move manually – Git updates them automatically during any network communication to ensure they accurately represent the state of the remote repository.
Think of them as bookmarks that remind you where the branches in your remote repositories were the last time you connected to them. For example, in the remote (GitHub), you might have a branch called my-branch represented as refs/heads/my-branch. When you clone or fetch the repository, you will have a local reference for the same branch as refs/remotes/origin/my-branch
The concept of remote-tracking branches exists only in your local repository. Therefore, there is no reason for a reference like refs/remotes/origin/my-branch to exist on GitHub (or others SCM platforms). This would be pointless because the same branch is hosted on GitHub as refs/heads/my-branch
To fully understand the issue with secrets that are accessible only via git clone --mirror, let’s delve into how git clone knows which references to fetch/map.
When you open the .git folder and look into the config file, you will see a line like this: fetch = +refs/heads/*:refs/remotes/origin/*. This line essentially tells Git to fetch all branches from the remote (in our case, GitHub) and map them to remote-tracking branches locally. As a result, when we clone a repository in the usual way, we get all the existing branches of the project.
In contrast, the configuration for git clone --mirror looks like this: fetch = +refs/*:refs/*. This means that every reference from the remote repository is fetched and mapped directly, including pull request references, remote-tracking branch references, and any other references.
In summary, using git clone --mirror brings in everything, including references not typically fetched by a standard clone. In contrast, git clone only brings branches that exist in the remote. This is why you might find different and new commits that can be accessed and scanned for sensitive data.
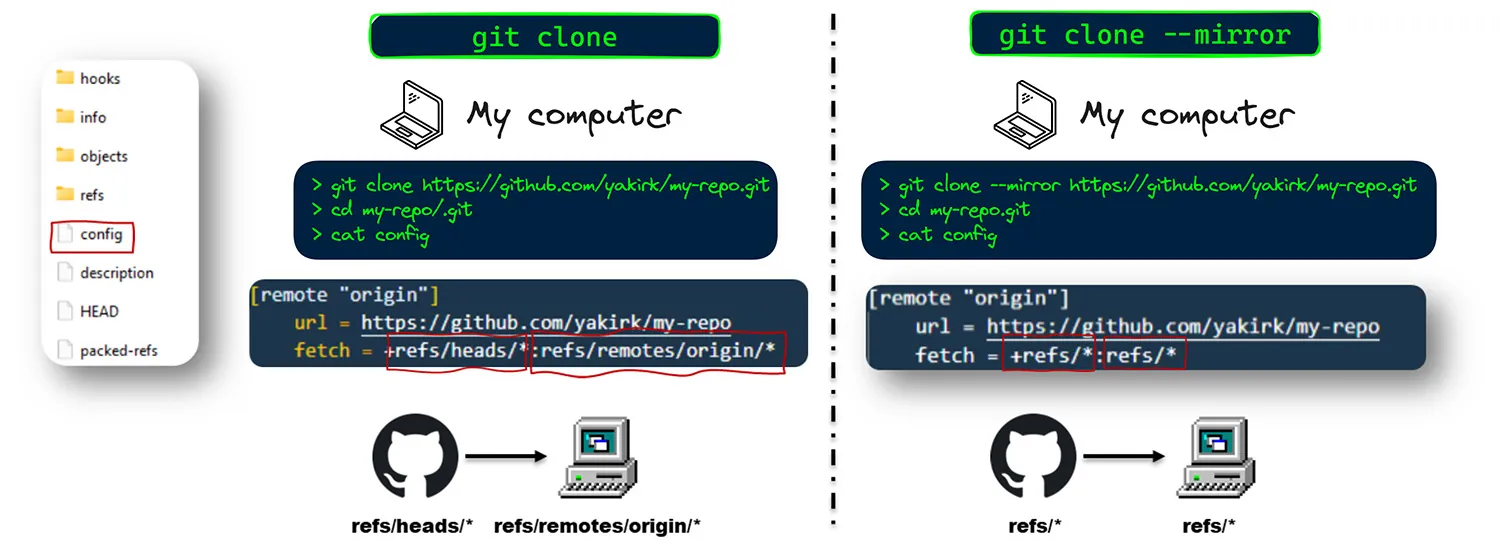
The difference between `git clone` and `git clone –mirror`
Now that we have some basic knowledge about Git internals, let’s describe the most common scenario that leads to secrets being exposed only in the mirrored version of our projects:
First Blind Spot: Pull Request References
GitHub stores information about pull requests in read-only reference in the following format: refs/pull/<pull_request_number>/head
As we mentioned before, this kind of reference will not be fetched in a regular clone but will be in a mirrored clone.
Pull request references remain forever and do not get deleted in the usual way (you will need GitHub support to delete them).
As a result, secrets present in a pull request’s history will not be exposed when scanning a Git repository using only a git clone command.
However, if a pull request containing secrets is merged into the project, these secrets become part of the branch history and will be detected since branches are fetched with a regular git clone. Additionally, if the pull request is not merged but is opened from a branch within the main project, the secrets will also be found because, as mentioned, branches are fetched during a git clone.
Nevertheless, the following secret scenario will only be accessible with a git clone --mirror:
- A pull request that contains a secret in its history is “closed” or “squashed and merged”, and the branch from which the pull request was created being deleted (it is very common to delete branches after the pull request is closed or merged).
- A pull request made from a fork. In this scenario, whether the pull request is open, closed, or squashed, there is no local branch in the scanned repository with the secret. Therefore, only a mirrored clone will fetch the pull request with the sensitive data.

List remote references of our Git project, including a reference to the pull request in refs/pull/1/head
Other platforms like GitLab and Azure Repos have similar references for pull requests.
For example, a merge request reference on GitLab is called refs/merge-requests/#{id}/head, but they behave differently. GitLab deletes merge request refs 14 days after being merged/closed, and Azure Repos delete these references if the pull request is deleted. However, if the pull request is rejected, these references will still be accessible with git clone --mirror.
Bitbucket and AWS CodeCommit do not have references for pull requests, but secrets can still be accessible via the GUI of all SCM platforms.
This raises another question: What is the best approach here? Should we have references to these PRs so we can scan them, or should we hide them/make them difficult to access? We need to remember that attackers have time and motivation.
Second Blind Spot: Dangling Remote Tracking Branch References
As we mentioned above, remote-tracking branches are references that reflect the state of remote branches. These are local-only references that shouldn’t exist on the remote. However, there are some edge cases that may cause them to appear on the remote, such as on GitHub, Bitbucket, Azure repos and more.
The GitBleed research provides two examples(1, 2), where secrets were found in mirrored versions of repositories. The common factor in these scenarios was the use of the git push --mirror command. Keep in mind that the git push --mirror is seldom used in practice and has different purposes than git push.
During our research, we discovered the reason why these scenarios led to secrets existing in the mirrored version of the repository. The command git push --mirror triggers an interesting behavior in both Git and some SCM platforms, which results in remote tracking branches being pushed to the SCM.
In general, consider the following scenario:
- You created a local branch.
- You mistakenly committed a sensitive data in the local branch.
- You pushed the local branch to the remote (GitHub).
- You noticed the mistake and deleted the local branch.
- You made
git push --mirror, which deletes the remote branch. But this command also creates a “dangling” new reference for the compromised branch in the remote.
In this scenario the secret will be visible only by git clone --mirror.
Let’s show how this looks with relevant commands. consider that you clone a project and then perform the following commands:

At this point, locally we have refs/heads/new-branch and refs/remotes/origin/new-branch, and remotely the repository named origin has refs/heads/new-branch – they all point to that mistake.
Then you noticed your mistake (secret committed) and you wish to delete it from the local and remote with the following command:

We get rid of the local refs/heads/new-branch and propagate the removal to origin by removing refs/heads/new-branch from it. However, because of the --mirror option, which synchronizes the local state to the destination, we also propagate refs/remotes/origin/new-branch. So, we push the remote-tracking branch local reference that points to the mistake to the remote, and now when a user clones the project with git clone --mirror, they will have access to this secret.
We might think that when we delete a local branch, we can expect to delete the remote-tracking branch as well, but this is not the case.
When we reported this behavior to the Git security team, they responded that this is a very old design decision, coming from a desire not to lose information even when the origin loses it, so that they can ask other who forked from them to see if anybody has what they lost by accident and recover it. Indeed, Git has many different use cases that we may not always be aware of or consider.
Git stated that the SCM platforms can prevent those remote-tracking branches from being pushed to remote by implementing pre-receive hooks to limit the hierarchy under refs/ they receive pushes into. We checked various popular SCM platforms and found that GitLab is the only SCM that blocks remote-tracking branch references from being pushed to the remote, and when you try to do so, you will get the following error message:

But GitHub, Bitbucket, Azure Repos, and more accept them, which, as we see, can lead to hidden secrets being exposed.
We have reported our findings to different SCM providers about how the git push --mirror command can lead to dangling remote references.
They responded that “This is an intentional design decision and is working as expected. We may make this functionality stricter in the future”.
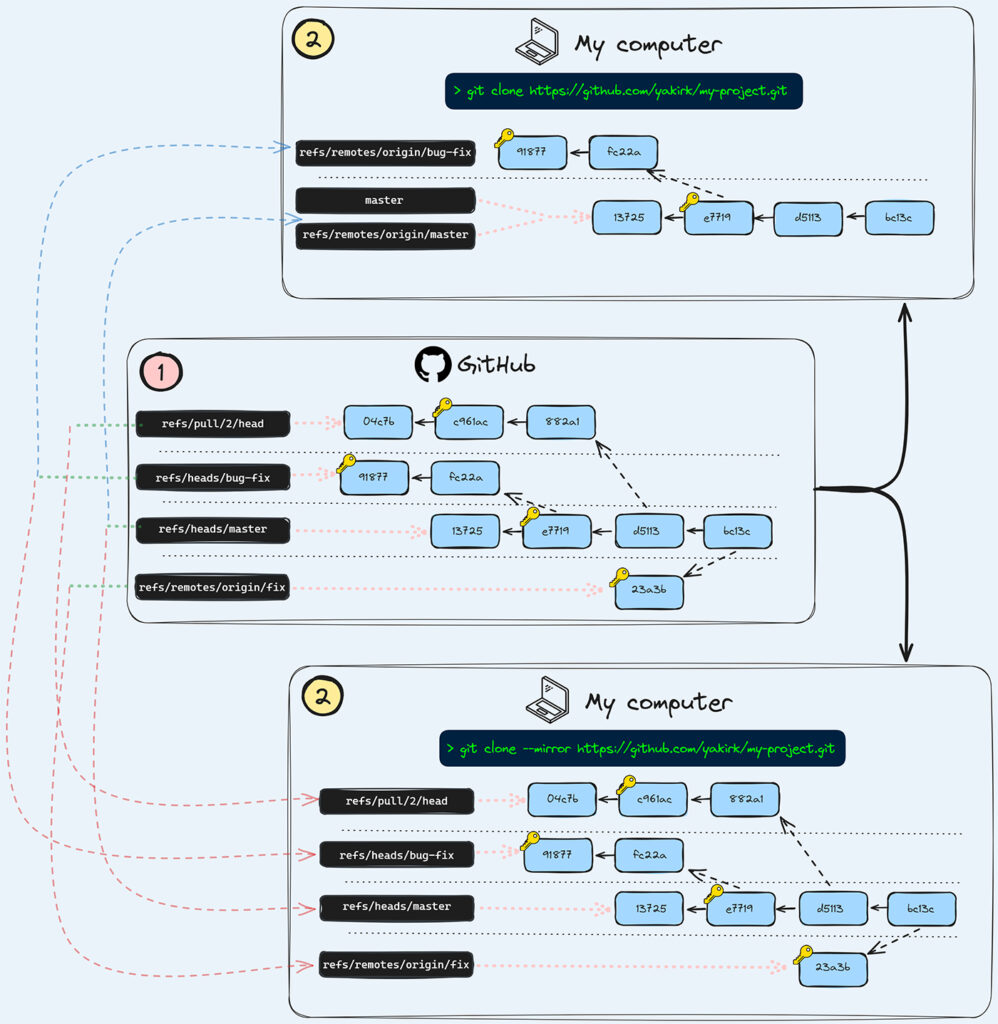
This chart illustrates how references are mapped from a remote repository (in this case, GitHub) to a local computer. As shown in the bottom section, using git clone — –mirror retrieves all available references. In contrast as shown in the upper section, a regular git clone omits some references that are present in the SCM platform
In summary, git clone --mirror allows us to fetch all the references that exist in the remote repository. Previously, we provided two examples: pull requests and remote-tracking branches. However, there are other references in Git and the SCM, such as notes, tags, and more that we didn’t mention, and secrets can exist on them too.
Statistics of Secrets Accessible Only via git clone – -mirror
To demonstrate the risk and the prevalence of the scenarios we mentioned, we analyzed how many of these hidden “mirrored” secrets exist. We scanned the top 100 organizations on GitHub, ranked by the number of stars, which together have 52,268 different repositories. We first scanned these repositories with Gitleaks using git clone, then we scanned them again using git clone –mirror. We counted the number of unique secrets, meaning those that only exist in the mirrored version of the repository. We found that if users only scan for secrets using a regular git clone, they will miss around 17.78% of the potential secrets in their repositories.*

Organizations that scan with git clone will miss an average of 17.78% of potential secrets
*It’s also important to mention that not every result from a secrets scanning tool is accurate, as there are many false positives. However, these results still need to be verified and considered by organizations. As we will show you, some of these results were significant (and this was after deciding to check only a few of them due to the huge number of potential new secrets).
Secrets that are accessible via cached views of SCM platforms
As clear as black and white: Everything committed to an SCM platform is permanent. Commits remain accessible through “cache views” on the SCM. Essentially, the SCM saves the commit content forever. This means that even if a secret containing commit is removed from both the cloned and mirrored versions of your repository, it can still be accessed if someone knows the commit hash. They can retrieve the commit content through the SCM platforms GUI and access the leaked secret.

The Iceberg of Secrets: The next layer of secrets exists in the of the SCM
The misconception that a commit is no longer visible can create a false sense of security, leading you to believe that no one can access it. However, as we will demonstrate, there are multiple ways to retrieve these seemingly inaccessible commits hashes.
Not long ago, Neodyme published a great blog post discussing this risk. Here, we will share additional findings on how different SCM platforms behave and realistic approaches to discovering cached view commits.
Here we will demonstrate four different strategies to retrieve cached view commits, ranked from the least likely to the most likely to encounter cached view commits:
1 – Brute forcing cached view commit hashes
Content of historic commits can be accessed online via the SCM GUI/API. Mind, that if you don’t know the commit hash, and choose to guess it, you only need to guess the four initial characters in order to be automatically redirected to the content of a commit that starts with these 4 characters (on GitHub), as discussed in the Neodyme blog.
In large projects, collisions with other commits starting with the same 4 characters can occur, resulting in a 404-error page. In such cases, we need to add one or two more characters to our guess until we find a commit. Once found, we can extract the full list of available commits from the mirrored version of our repository. If a commit is not present in the mirrored version, it indicates that it is a cached view commit, which might contain interesting content.
It is important to note that this brute force approach can be time-consuming, especially when facing rate limits on the remote server.
On other SCM platforms we found similar behavior: On Bitbucket, you only need to guess too the first 4 characters of the hash. On GitLab, you need to guess the first 7 characters. However, on Azure Repos and AWS CodeCommit, this method is not feasible because you need to guess the full hash.
2 – Using REST API endpoints for event
GitHub provides a REST API that allows us to list repository events, which enable searching for commit hashes. Neodyme reported in their blog about a tool they created to find these hashes.
The Events API has significant limitations. Firstly, it will only show the most recent 90 days or up to 300 events, whichever is fewer. This restricts the scope of what can be retrieved and analyzed.
3 – GUI of Pull requests
This scenario was discovered by our research team. Two common ways to “delete secrets” after they were committed is:
git reset --hard HEAD~{number_of_commits}followed bygit push --force.git commit --amendfollowed bygit push --force(after editing the file with the secret)
However, when these actions are performed on a branch that has an open pull request, it leaves traces in the GUI that reveal the cached view commit hash. This makes it possible to harvest these hashes and search for secrets within them. In this scenario, the hash of the commit will not be accessible via the cloned or mirrored version of the repository but can be harvested from the GUI of the SCM.
All you need to do is search for a string like force-pushed the {branch_name} branch from {commit_hash} to {commit_hash} in the Pull Request GUI. The interesting commit hash is the first one, as it is typically the cached view.
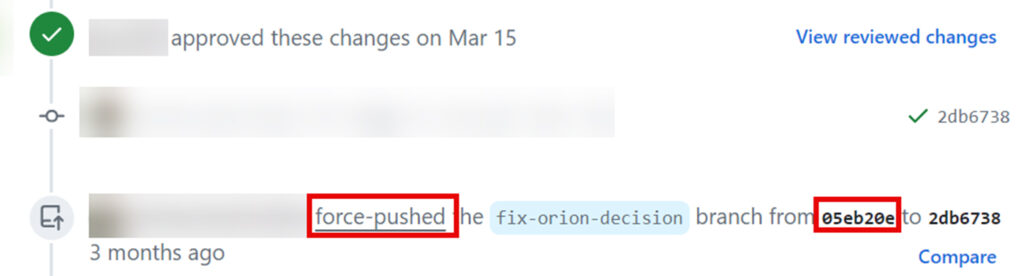
It is possible to harvest cached view commits by looking for the word ‘force-pushed’ in the pull requests and extracting the first commit hash
If you want to do this, you must read GitHub’s scraping policy, as this information is only available by scraping each PR on github.com and is not available via the official API.
4 – Using GitHub historical dataset
This strategy was discovered by our research team. The most efficient way to find cached view commits is by utilizing GitHub’s historical dataset and checking past commits records of your repositories. We used this dataset in the past to successfully identify security gaps, such as finding millions of vulnerable repositories to RepoJacking.
In our use case, anyone can collect every commit ever recorded for a target repository and then verify if these commits are included in the mirrored version. If a commit is not present in the mirrored version, it would be a good idea to fetch this commit from GitHub and scan it for secrets.
The collection covers a 9-year data ranging between 2013 and 2021. This is a significant timeframe which contains a lot of records in which one can find hash view commit, that may contain a live secret.
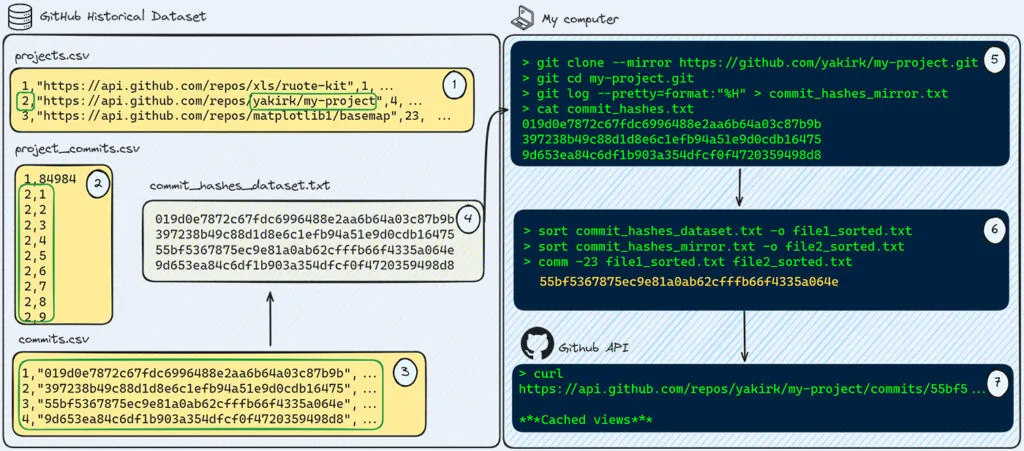
How to extract potential cached commits with GitHub historical dataset
Potential steps needed to retrieve specific commits:
- Download the dataset and extract the following three tables:
project.csv,project_commits.csv, andcommits.csv.
- Search for repositories of your organization to get the related ID of the in the dataset.
- From
project_commits.csv, obtain the IDs (not the hashes) of the commits related to a target repository.
- Retrieve the commit hashes from commits.csv to get a full list of commits for a target repository to be scanned for cached view commits.
- Clone the target project using
git clone --mirrorand extract each commit that exists in the mirror version.
- Identify only the commits that are in the dataset but not in the mirror (because there are commits that exist in the mirror but not in the dataset, as the dataset is only up to around 2021).
- Utilize the GitHub API to get the content of the cached view of each commit and scan each the blob within the commit using a secret scanning tool.
While this process is complicated and resource consuming and the odds of finding secrets are rather low, it is still a great way to detect forgotten secrets, that won’t be found otherwise.
Summary and Mitigations
Secrets remain one of the most sought-after targets for attackers because they are powerful and often the low-hanging fruit. In this blog, we explored various strategies to uncover secrets that may otherwise be hidden for years.
We would like to mention that prevention is the best defense, but we must also review the history of our repositories for secrets, especially if they are public, to eliminate any secrets and traces that attackers could exploit.
To better protect your code and infrastructure, we offer the following mitigation and strategies to address the various risks and scenarios discussed in this blog.
While we will focus on GitHub repositories since they are more likely to be public, these steps are also applicable to other SCM platforms like GitLab, Bitbucket, Azure Repos, etc.
- If you accidentally push a secret to SCM, you should consider it compromised and rotate it immediately. As we have shown, even if you try to hide the commit containing the secret using git commands or tools like BFG or git-filter-repo, there are still ways to retrieve these commits and access them through cached views on SCM platforms.
- While it may take a long time and is a less practical action to take, to completely delete secrets from GitHub, you will need to contact GitHub support. This is relevant for most SCM platforms as well.
- Try adopting internal features of the SCMs, such as using push protection.
- Set up pre-commit hooks to scan for secrets before every commit. This helps preventing accidental exposure of sensitive information in your repository.
Mitigations for Secrets Accessible Only via git clone – -mirror
- Scan your repository for secrets by using the
git clone --mirroroption. - Only few secrets scanning tools support scanning bare repositories, below is an example of a couple of them (Gitleaks and TruffleHog).
Gitleaks example

TruffleHog – the option to scan bare repositories was added recently:

- As a first step, we suggest you scan the delta between the regular clone and the mirrored clone, as it may contain hidden secrets. The author of GitBleed gave an example for this concept with the following tool (powered by Gitleaks). Naturally you can utilize other secrets scanners under the same concept.
Focus on secrets unique to the mirror version by checking the delta with the cloned version
- Deleting secrets from pull request references: As we mentioned earlier, when a secret is committed to an SCM platform, the commit remains there permanently as a cached view. However, if you still want to hide the commit and rewrite the history, you can use tools like BFG or git-filter-repo. In the case of secrets in pull requests, these tools will be insufficient, as they cannot delete the read-only pull request references on the remote by themselves. To delete pull request references that contain secrets, users need to de-reference and delete the compromised references. However, this option is available only to GitHub Enterprise Admins.
- Users seeking to remove secrets from pull requests in public or private repositories on GitHub.com will need to contact GitHub Support for assistance.
- For those using GitHub Enterprise, a comprehensive tutorial is available on how to de-reference and delete pull requests from your GitHub server.
- Deleting Secrets from Dangling Remote Tracking Branch References: To delete secrets from dangling remote tracking branch references, start by listing all references in the remote using
git ls-remote. Look for any references that start with theprefixrefs/remotes/origin/{branch_name}. If you find such references, check them for secrets. If a reference contains secrets, delete it from the remote using the commandgit push origin:refs/remotes/origin/{branch_name}. - Mitigations for Secrets Accessible Only via cached views: Ensure that no exposed commits went unnoticed, it is advisable to utilize GitHub’s dataset or scan pull requests for force-pushed commits.
Aqua Solution
Available in August, Aqua customers using the Software Supply Chain Security module will be able to prevent developers from committing code with embedded secrets, and scan for phantom secrets hidden within their SCM file system.
Source: https://www.aquasec.com/blog/undetected-hard-code-secrets-expose-corporations
“An interesting youtube video that may be related to the article above”