Summary: This article discusses the concept of polyglot files, which are files that can be interpreted as multiple file types simultaneously, and the potential security implications they pose.
Threat Actor: N/A
Victim: N/A
Key Point :
- Polyglot files are designed to exploit the way different file formats are interpreted by different software, allowing them to bypass security measures and potentially execute malicious code.
- These files can be used in various cyber attacks, including phishing campaigns, malware distribution, and data exfiltration.
kochlr@ornl.gov
Oak Ridge National Laboratory
Oak Ridge, TN, USA
oeschts@ornl.gov
Oak Ridge National Laboratory
Oak Ridge, TN, USA
chaulagaina@ornl.gov
Oak Ridge National Laboratory
Oak Ridge, TN, USA
dixonjm@ornl.gov
Oak Ridge National Laboratory
Oak Ridge, TN, USA
dixsonmk@ornl.gov
Oak Ridge National Laboratory
Oak Ridge TN, USA
huettelmr@ornl.gov
Oak Ridge National Laboratory
Oak Ridge, TN, USA
sadovnika@ornl.gov
Oak Ridge National Laboratory
Oak Ridge, TN, USA
watsoncl1@ornl.gov
Oak Ridge National Laboratory
Oak Ridge, TN, USA
weberb@ornl.gov
Oak Ridge National Laboratory
Oak Ridge, TN, USA
hartmanj@ainfosec.com
Assured Information Security
Rome, New York, USA
patulskir@ainfosec.com
Assured Information Security
Rome, New York, USA
Abstract
A polyglot is a file that is valid in two or more formats. Polyglot files pose a problem for malware detection systems that route files
to format-specific detectors/signatures, as well as file upload and sanitization tools. In this work we found that existing file-format and embedded-file detection tools, even those developed specifically for polyglot files, fail to reliably detect polyglot files used in the wild, leaving organizations vulnerable to attack. To address this issue, we studied the use of polyglot files by malicious actors in the wild, finding 30303030 polyglot samples and 15151515 attack chains that leveraged polyglot files. In this report, we highlight two well-known APTs whose cyber attack chains relied on polyglot files to bypass detection mechanisms. Using knowledge from our survey of polyglot usage in the wild—the first of its kind—we created a novel data set based on adversary techniques. We then trained a machine learning detection solution, PolyConv, using this data set. PolyConv achieves a precision-recall area-under-curve score of 0.9990.9990.9990.999 with an F1 score of 99.2099.2099.2099.20% for polyglot detection and 99.4799.4799.4799.47% for file-format identification, significantly outperforming all other tools tested. We developed a content disarmament and reconstruction tool, ImSan, that successfully sanitized 100100100100% of the tested image-based polyglots, which were the most common type found via the survey. Our work provides concrete tools and suggestions to enable defenders to better defend themselves against polyglot files, as well as directions for future work to create more robust file specifications and methods of disarmament.
Keywords File-format Identification, Malware Detection, Polyglot Files, Machine Learning, APT Survey, Content Disarmament and Reconstruction
1 Introduction

Figure 1: Functionality of a polyglot file is determined by the calling program, which can be explicitly provided or automatically determined by the operating system’s auto-launch settings.
A polyglot file simultaneously conforms to two or more file-format specifications. This means the polyglot file can exhibit two completely different sets of behavior depending on the calling program, as depicted in Figure 1. This dual nature poses a threat to endpoint detection and response tools (EDR) and file-upload systems that rely on format identification prior to analysis. As shown in Figure 2, a polyglot can evade correct classification by first evading format identification. If only one format is detected, then the sample may not be routed to the correct feature-extraction routine (in the case of machine learning-based detectors) or compared to the correct subset of malware signatures (in the case of signature-based malware detection).
As evidence that existing commercial off-the-shelf (COTS) endpoint detection and response tools are vulnerable to polyglots, we point to Bridges et al. [Bridges et al.(2020)], who demonstrated that 4 competitive COTS tools detected 0% of the malicious polyglots in the test data.
Standardized formats for files play a key role in cybersecurity.
By first identifying the format of an unknown sample, they allow malware detection tools to extract the most discriminate and robust features from an unknown sample. This allows the detection tool to discard unimportant bytes that can be manipulated to alter classification in an adversarial attack [Kolosnjaji et al.(2018), Demetrio et al.(2021)].
However, this feature-extraction process introduces a vulnerability; the correct format must be detected in order to route the file to the correct feature extractor.
Even when a detector does not use machine learning and instead relies upon signatures for detection, the need to maintain a high throughput encourages EDR tools to only search for signatures that correspond to the detected format [Jana and Shmatikov(2012)].
As prior researchers [Jana and Shmatikov(2012), Albertini(2015), Clunie(2019), Ortiz(2019), Desjardins et al.(2020), Popescu(2012b)] have demonstrated, polyglot files can be crafted that are fully valid (execute as intended) in multiple formats.
To date, however, no comprehensive study of polyglot usage by malicious actors in the wild and/or methods of detecting said polyglots has been undertaken.
In this paper, we set out to answer four key research questions related to polyglot usage and mitigation:
RQ1: How are polyglots currently used by threat actors in the wild? This includes the role the polyglot fills, the formats of the donor files, and the combination method used to fuse the donors together.
RQ2: Can we train a detector to effectively filter or reroute polyglots prior to ingestion by a malware detection system?
RQ3: Does this detector outperform existing file type detection, file carving, and polyglot-aware analysis tools at detecting polyglot files?
RQ4: Given the prevalence of image-based polyglots in adversary usage and the relative simplicity of image formats, what tools can we provide to defenders to address image-based polyglots in their existing workflows?
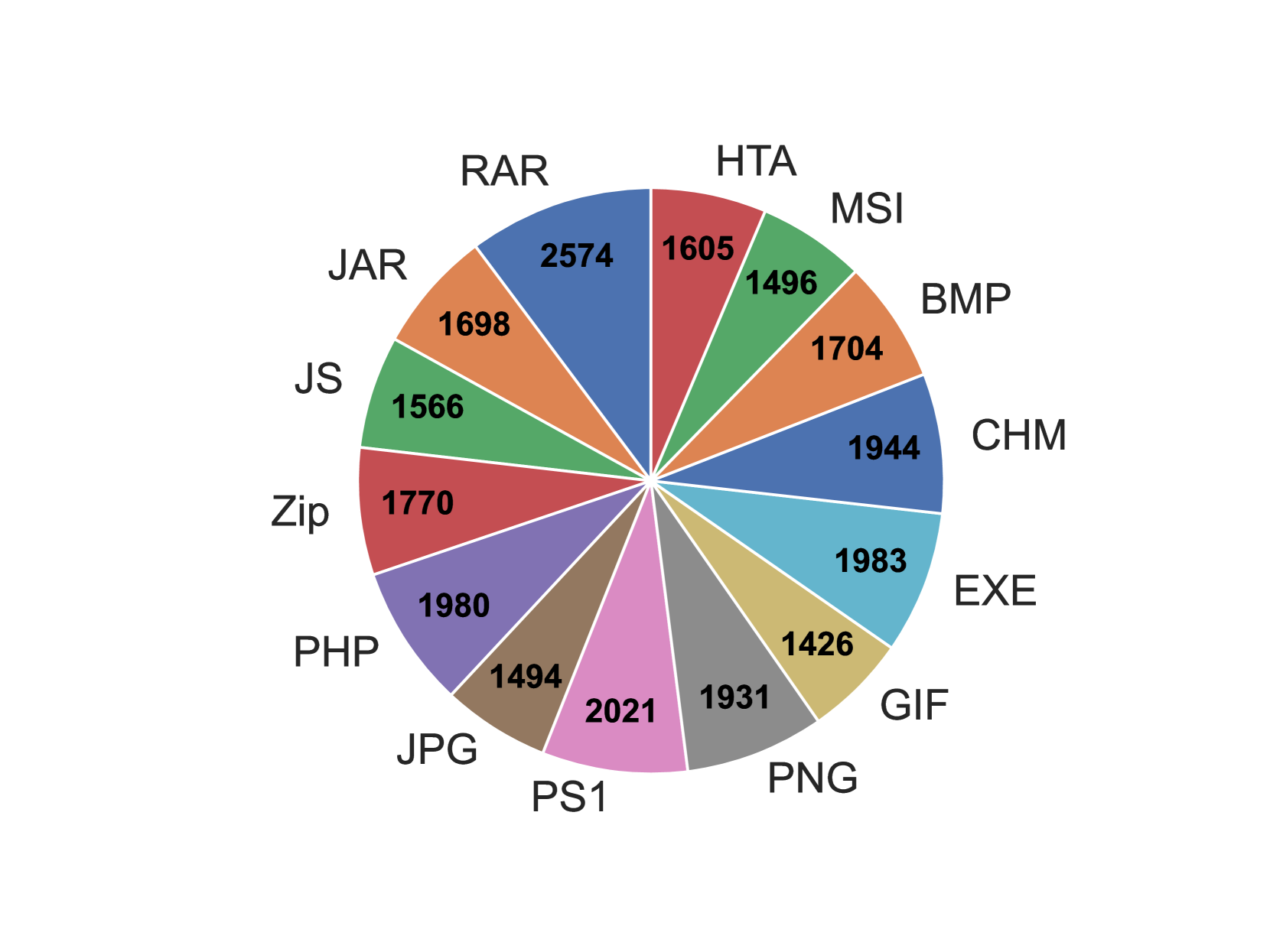
To address RQ1, we reviewed open-source intelligence feeds (see Section 3.1 for methods) that detail adversary tactics, techniques and procedures (TTP), finding that polyglots have played an important role in a number of malicious campaigns by well-known advanced persistent threat (APT) groups.
Polyglot files allowed the malicious actors to covertly execute malicious activity and extract sensitive data by masquerading as innocuous formats.
In Section 3, we provide an overview of the different roles polyglots played in each campaign, detail the file combinations used, and provide a detailed description of several high profile examples.
To address RQ2-RQ4, we first created a tool, Fazah, for generating polyglots that mimic the examples seen in the wild. Although there are other possible format combinations, our goal with this tool was to mimic, as closely as possible, the formats and combination methods used by real-world threat actors.
Using this tool, we then created a data set of polyglot and normal (referred to hereafter as monoglot) files for training and testing. See Section 4 for a full description of the data set.
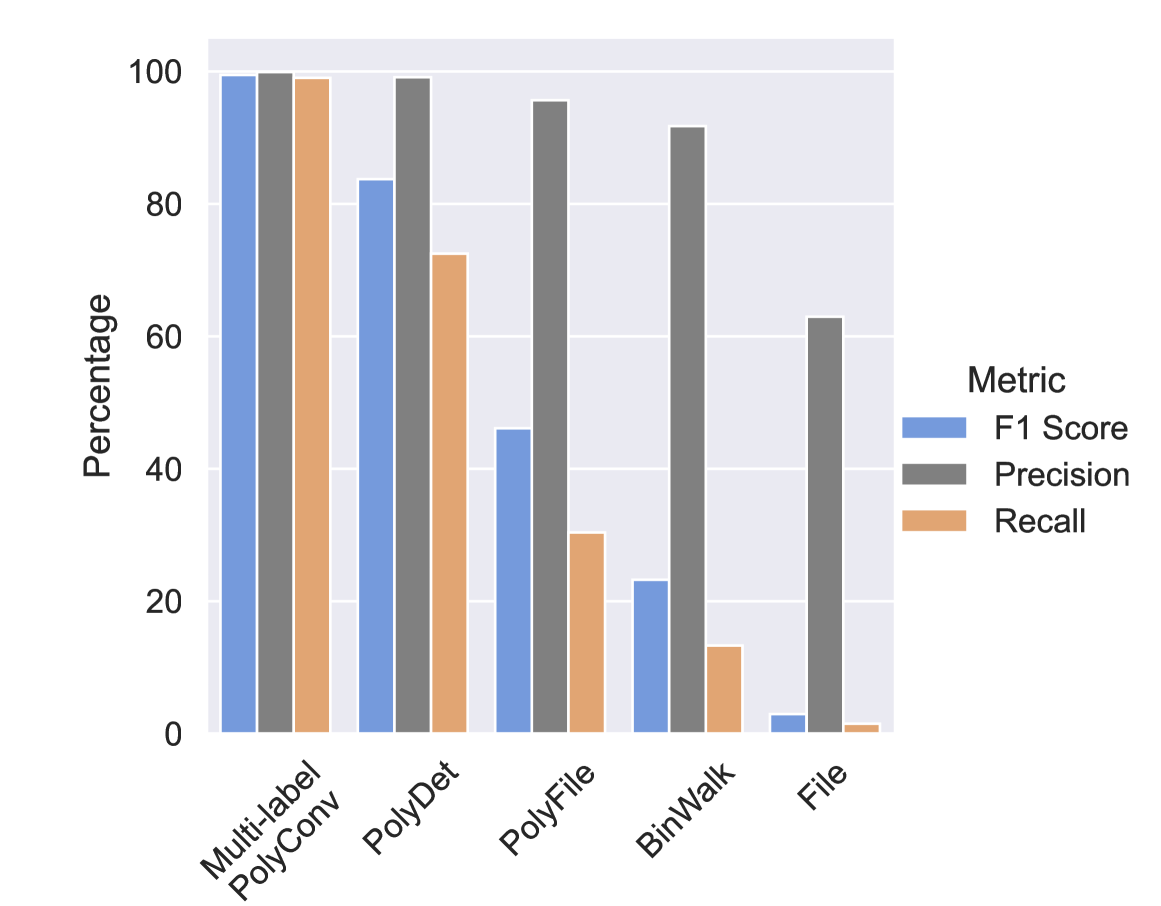
To address RQ2, we tested machine learning models to solve both the binary and the multi-label classification problems, achieving an F1 score of 99.20% for binary classification and 99.47% for multi-label classification with our deep learning model PolyConv.
To address RQ3, we evaluated five commonly used format identification tools on this dataset: file [Darwin et al.(2019)], binwalk [ReFirmLabs(2021)], TrID, polydet, and polyfile. These tools were selected because of their use in existing cybersecurity tools or claim to detect polyglot files.
We evaluated the performance of these tools at both binary and multi-label classification.
In our context, binary classification determines whether a file is a polyglot or a monoglot. Multi-label classification, on the other hand, identifies all formats to which the file conforms.
We found that existing tools did not exceed an F1 score of 93.32% at binary classification and 83.74% at multi-label classification.
See Section 5 for details regarding our ML based approaches and Section 6 for a comparison of ML-based approaches to existing file-format identification tools.
As detailed in Section 7, to address RQ4 we developed and tested a CDR tool for sanitizing image-based polyglots since these were the most common vector for polyglot malware. We also tested YARA rules for detecting extraneous content in image files.
We found that the YARA rule approach did not generalize well to all formats that can be combined with an image, especially the more flexible scripting formats like Powershell or JavaScript. However, they may be use in high-throughput use cases where deploying a deep learning model is not feasible.
A more effective approach is to strip all extraneous content from images using a content disarmament and reconstruction (CDR) tool. Our CDR tool, ImSan, was able to sanitize all of the image polyglots in a random subset of our image polyglots. A subset was used so we could manually verify the results.
The following provides a summary of our contributions:
-
•
RQ1: The first, to our knowledge, survey of polyglot usage by malicious actors in the wild, demonstrating that polyglot files are an actively used TTP by well-known malicious actors.
Utilizing the results of this study, we created a tool, Fazah, to generate polyglots using formats and combination methods exploited by malware authors in the wild.
We then used Fazah to generate a dataset of polyglots and monoglots to evaluate existing detection methods and train polyglot detection models. -
•
RQ2: Utilizing this novel dataset, we trained a deep learning model, PolyConv, that can distinguish between polyglots and monoglots with an AUC score over 0.999.
We also created a multi-label model that reports all of the detected formats in monoglot and polyglot files, enabling analysts to quickly determine the nature of a threat or route the suspicious file to multiple format-specific detection systems. -
•
RQ3: We provide a comparison of our polyglot detection models with existing file-format identification and carving tools, some of which are polyglot aware.
This evaluation shows that existing methods for detecting file type manipulation are inadequate and often fail to detect polyglot files, even with special flags set that are meant to ensure multiple file types are detected. -
•
RQ4: For image-based polyglots, which are common in the wild, we explored YARA rules and content disarmament and reconstruct (CDR) tools, finding that our ImSan CDR tool was 100% effective while the YARA rules did not compete with our deep learning detector. They may, however, be of use in high throughput situations.